OOP Object Relations¶
pickle- has relationsjson- has relationscsv- non-relational format
- normalization¶
Database normalization is the process of structuring a database, usually a relational database, in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity. Normalization entails organizing the columns (attributes) and tables (relations) of a database to ensure that their dependencies are properly enforced by database integrity constraints. It is accomplished by applying some formal rules either by a process of synthesis (creating a new database design) or decomposition (improving an existing database design). A relational database relation is often described as "normalized" if it meets third normal form. [1] [4]
- big-data¶
Big data is a field that treats ways to analyze, systematically extract information from, or otherwise deal with data sets that are too large or complex to be dealt with by traditional data-processing application software. Data with many fields (columns) offer greater statistical power, while data with higher complexity (more attributes or columns) may lead to a higher false discovery rate. Big data analysis challenges include capturing data, data storage, data analysis, search, sharing, transfer, visualization, querying, updating, information privacy, and data source. Big data was originally associated with three key concepts: volume, variety, and velocity. The analysis of big data presents challenges in sampling, and thus previously allowing for only observations and sampling. Therefore, big data often includes data with sizes that exceed the capacity of traditional software to process within an acceptable time and value. [5]
- retention¶
Data retention defines the policies of persistent data and records management for meeting legal and business data archival requirements. In the field of telecommunications, data retention generally refers to the storage of call detail records (CDRs) of telephony and internet traffic and transaction data (IPDRs) by governments and commercial organisations. In the case of government data retention, the data that is stored is usually of telephone calls made and received, emails sent and received, and websites visited. Location data is also collected. [6]
- relation¶
In relational database theory, a relation, as originally defined by E. F. Codd, [4] is a set of tuples (d1, d2, ..., dn), where each element dj is a member of Dj, a data domain. Codd's original definition notwithstanding, and contrary to the usual definition in mathematics, there is no ordering to the elements of the tuples of a relation. Instead, each element is termed an attribute value. An attribute is a name paired with a domain (nowadays more commonly referred to as a type or data type). An attribute value is an attribute name paired with an element of that attribute's domain, and a tuple is a set of attribute values in which no two distinct elements have the same name. Thus, in some accounts, a tuple is described as a function, mapping names to values. [7]
- consistency¶
Consistency (or Correctness) in database systems refers to the requirement that any given database transaction must change affected data only in allowed ways. Any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof. This does not guarantee correctness of the transaction in all ways the application programmer might have wanted (that is the responsibility of application-level code) but merely that any programming errors cannot result in the violation of any defined database constraints. [11] [8]
- integrity¶
Data integrity is the maintenance of, and the assurance of, data accuracy and consistency over its entire life-cycle and is a critical aspect to the design, implementation, and usage of any system that stores, processes, or retrieves data. The term is broad in scope and may have widely different meanings depending on the specific context – even under the same general umbrella of computing. It is at times used as a proxy term for data quality, while data validation is a prerequisite for data integrity. Data integrity is the opposite of data corruption. The overall intent of any data integrity technique is the same: ensure data is recorded exactly as intended (such as a database correctly rejecting mutually exclusive possibilities). Moreover, upon later retrieval, ensure the data is the same as when it was originally recorded. In short, data integrity aims to prevent unintentional changes to information. Data integrity is not to be confused with data security, the discipline of protecting data from unauthorized parties. [10] [9]
- SQL¶
- Structured Query Language¶
Domain-specific language used in programming and designed for managing data held in a relational database management system (RDBMS), or for stream processing in a relational data stream management system (RDSMS). It is particularly useful in handling structured data, i.e. data incorporating relations among entities and variables. [2] [3]
- RDBMS¶
Relational Database Management System https://en.wikipedia.org/wiki/Relational_database#RDBMS
- RDSMS¶
Relational Data Stream Management System https://en.wikipedia.org/wiki/Relational_data_stream_management_system
- SELECT¶
SQL language operation to retrieve data from the database
- INSERT¶
SQL language operation to put data to the database
- UPDATE¶
SQL language operation to modify data in the database
- JOIN¶
SQL language operation to retrieve data from the database from multiple tables and merge them
- DBA¶
DataBase Administrator
Base¶
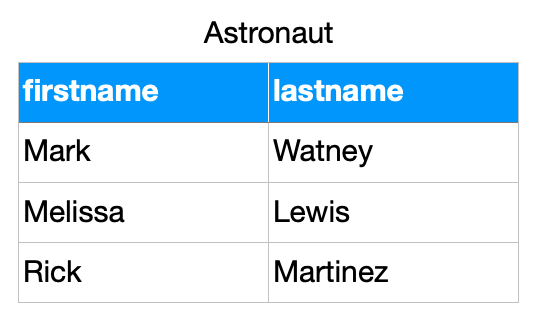
>>> from dataclasses import dataclass
>>>
>>>
>>> @dataclass
... class Astronaut:
... firstname: str
... lastname: str
>>>
>>>
>>> CREW = [
... Astronaut('Mark', 'Watney'),
... Astronaut('Melissa', 'Lewis'),
... Astronaut('Rick', 'Martinez'),
... ]
Extend¶
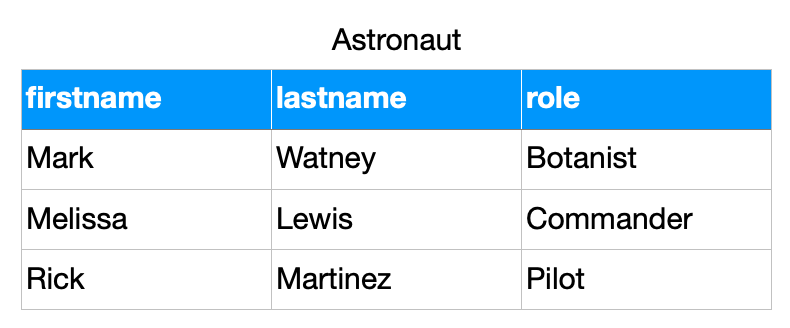
>>> from dataclasses import dataclass
>>>
>>>
>>> @dataclass
... class Astronaut:
... firstname: str
... lastname: str
... role: str
>>>
>>>
>>> CREW = [
... Astronaut('Mark', 'Watney', 'Botanist'),
... Astronaut('Melissa', 'Lewis', 'Commander'),
... Astronaut('Rick', 'Martinez', 'Pilot'),
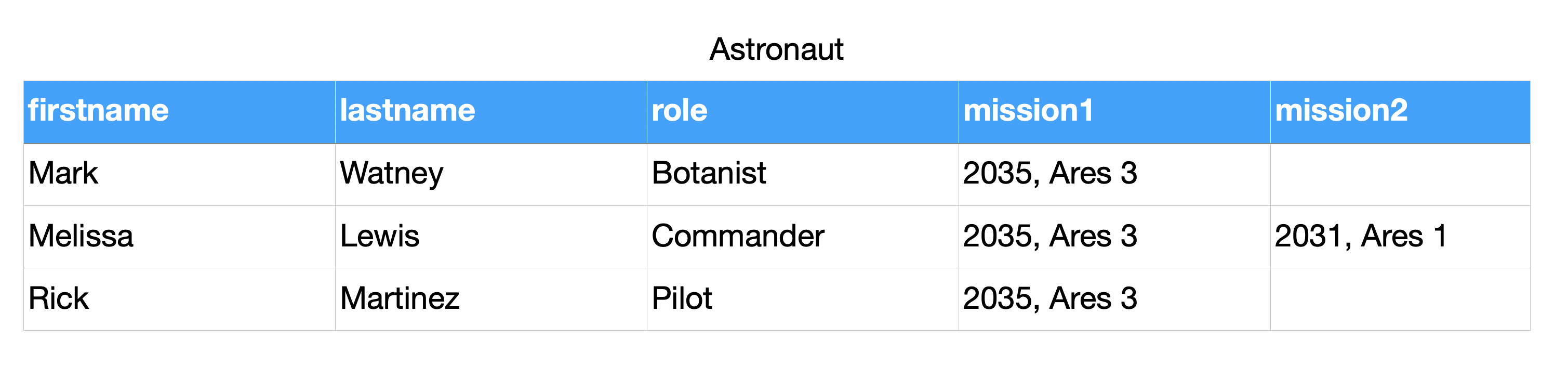
... ]
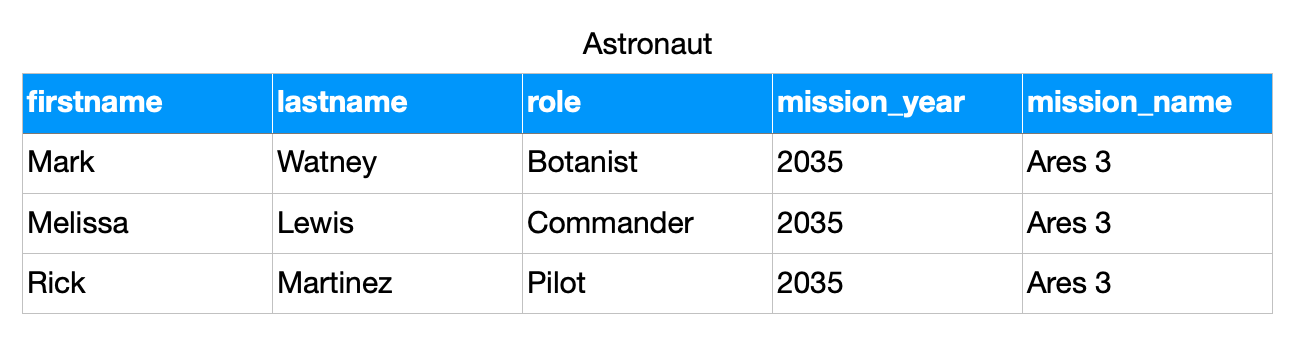
>>> from dataclasses import dataclass
>>>
>>>
>>> @dataclass
... class Astronaut:
... firstname: str
... lastname: str
... role: str
... mission_year: int
... missions_name: str
>>>
>>>
>>> CREW = [
... Astronaut('Mark', 'Watney', 'Botanist', 2035, 'Ares 3'),
... Astronaut('Melissa', 'Lewis', 'Commander', 2035, 'Ares 3'),
... Astronaut('Rick', 'Martinez', 'Pilot', 2035, 'Ares 3'),
... ]
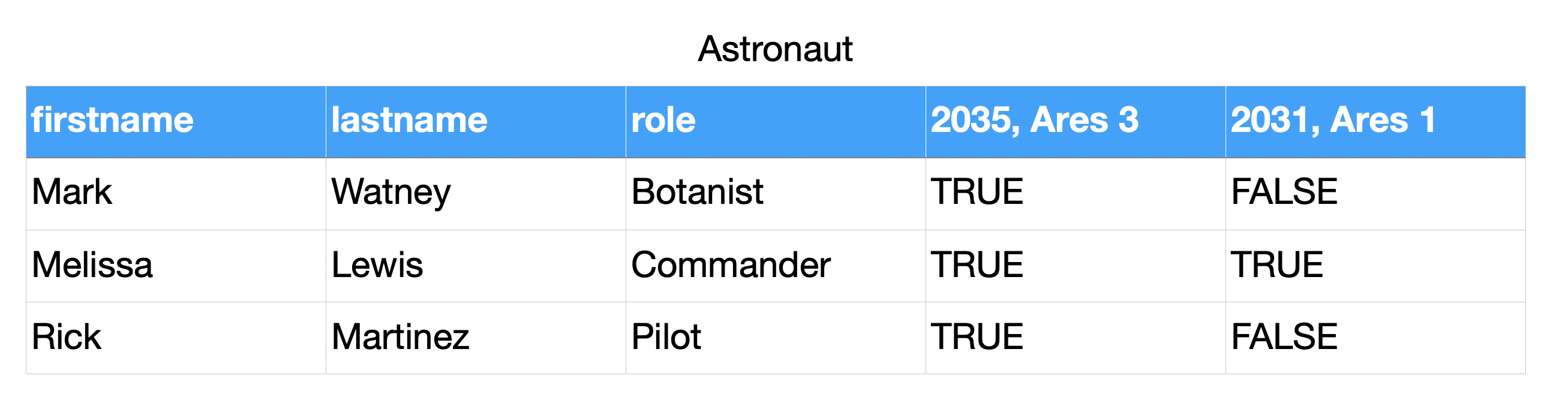
Boolean Vector¶
>>> from dataclasses import dataclass
>>>
>>>
>>> @dataclass
... class Mission:
... year: int
... name: str
>>>
>>>
>>> @dataclass
... class Astronaut:
... firstname: str
... lastname: str
... role: str
... missions: list[Mission]
>>>
>>>
>>> CREW = [
... Astronaut('Mark', 'Watney', 'Botanist', missions=[
... Mission(2035, 'Ares 3')]),
... Astronaut('Melissa', 'Lewis', 'Commander', missions=[
... Mission(2035, 'Ares 3'),
... Mission(2031, 'Ares 1')]),
... Astronaut('Rick', 'Martinez', 'Pilot', missions=[])]
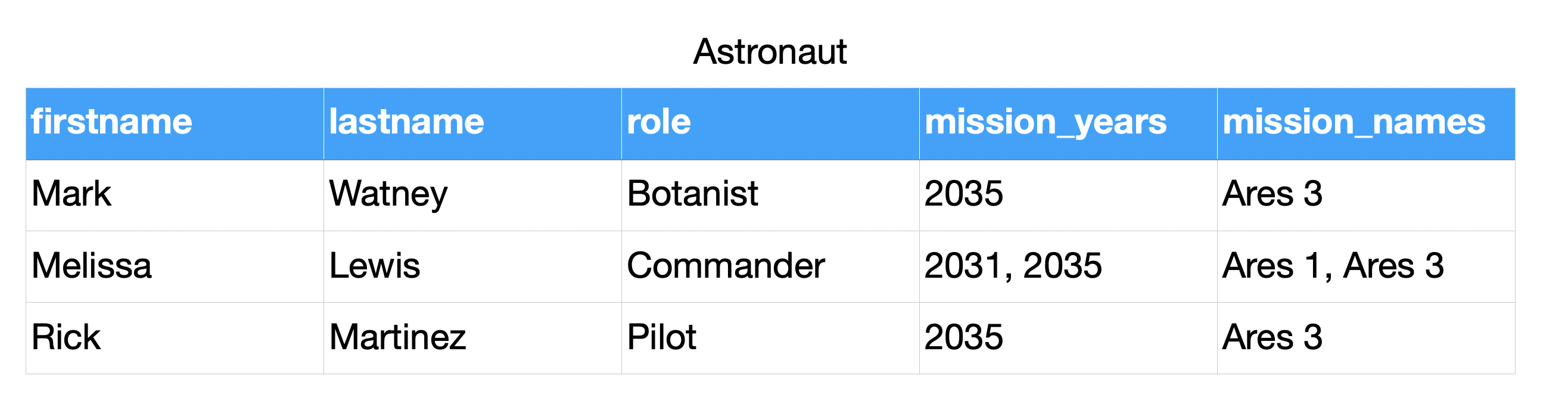
FFill¶
>>> from dataclasses import dataclass
>>>
>>>
>>> @dataclass
... class Mission:
... year: int
... name: str
>>>
>>>
>>> @dataclass
... class Astronaut:
... firstname: str
... lastname: str
... role: str
... missions: list[Mission]
>>>
>>>
>>> CREW = [
... Astronaut('Mark', 'Watney', 'Botanist', missions=[
... Mission(2035, 'Ares 3')]),
... Astronaut('Melissa', 'Lewis', 'Commander', missions=[
... Mission(2035, 'Ares 3'),
... Mission(2031, 'Ares 1')]),
... Astronaut('Rick', 'Martinez', 'Pilot', missions=[])]
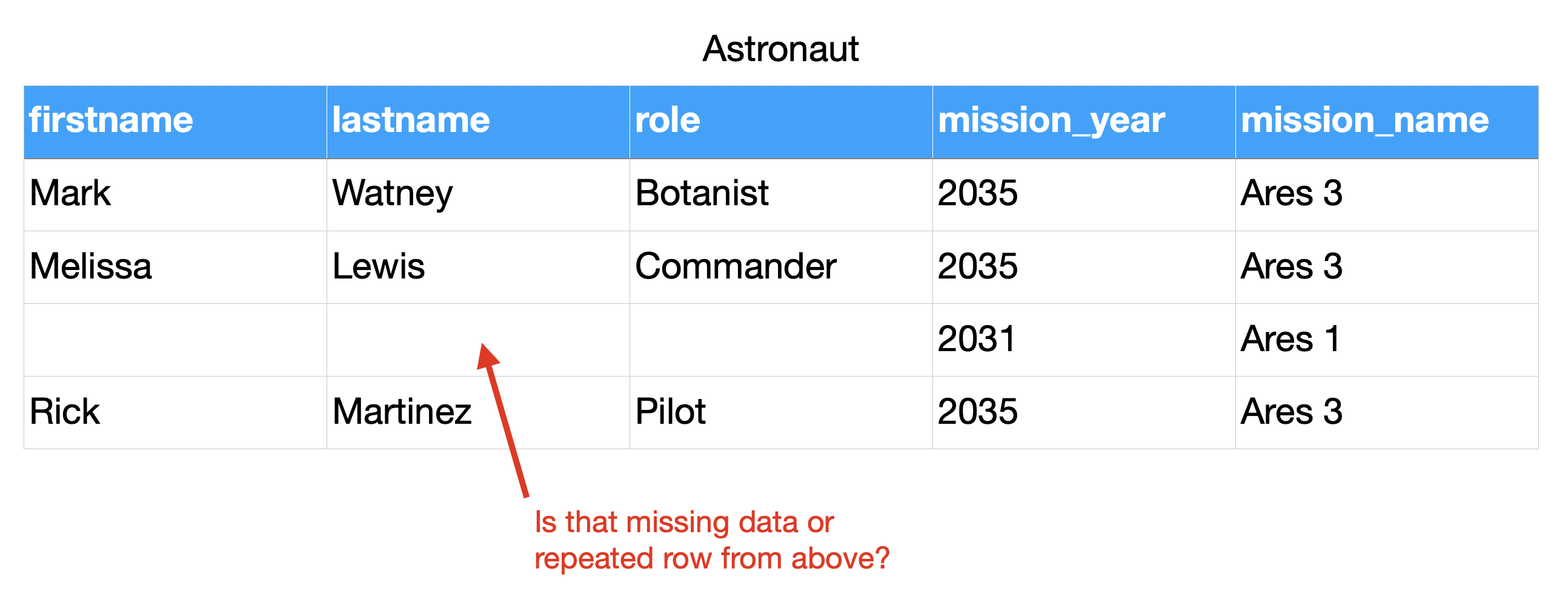
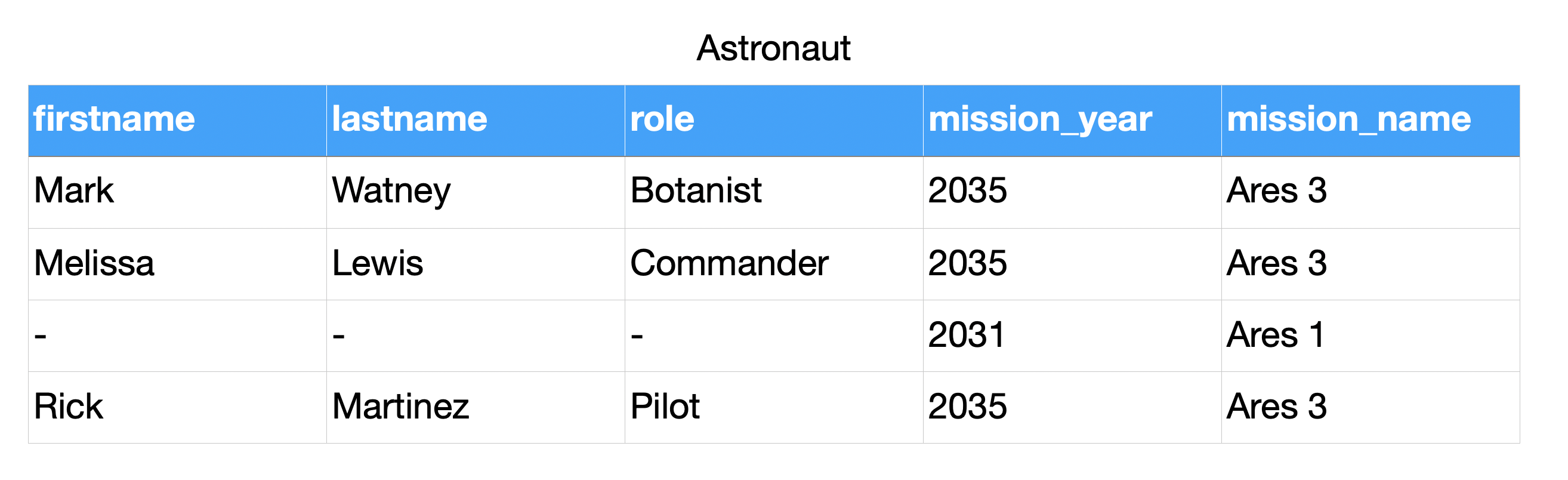

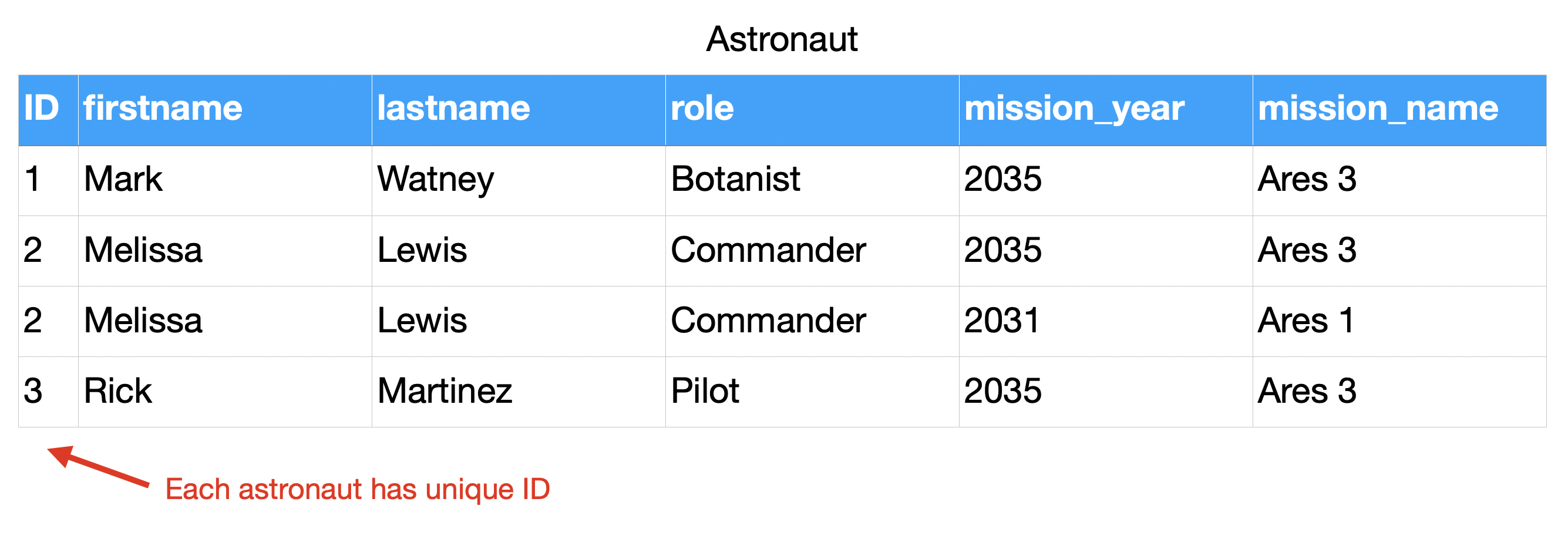
Relations¶
>>> from dataclasses import dataclass
>>>
>>>
>>> @dataclass
... class Mission:
... year: int
... name: str
>>>
>>>
>>> @dataclass
... class Astronaut:
... firstname: str
... lastname: str
... role: str
... missions: list[Mission]
>>>
>>>
>>> CREW = [
... Astronaut('Mark', 'Watney', 'Botanist', missions=[
... Mission(2035, 'Ares 3')]),
... Astronaut('Melissa', 'Lewis', 'Commander', missions=[
... Mission(2035, 'Ares 3'),
... Mission(2031, 'Ares 1')]),
... Astronaut('Rick', 'Martinez', 'Pilot', missions=[])]


Serialization¶
>>> from dataclasses import dataclass
>>>
>>>
>>> @dataclass
... class Mission:
... year: int
... name: str
>>>
>>>
>>> @dataclass
... class Astronaut:
... firstname: str
... lastname: str
... role: str
... missions: list[Mission]
>>>
>>>
>>> CREW = [
... Astronaut('Mark', 'Watney', 'Botanist', missions=[
... Mission(2035, 'Ares 3')]),
... Astronaut('Melissa', 'Lewis', 'Commander', missions=[
... Mission(2035, 'Ares 3'),
... Mission(2031, 'Ares 1')]),
... Astronaut('Rick', 'Martinez', 'Pilot', missions=[])]
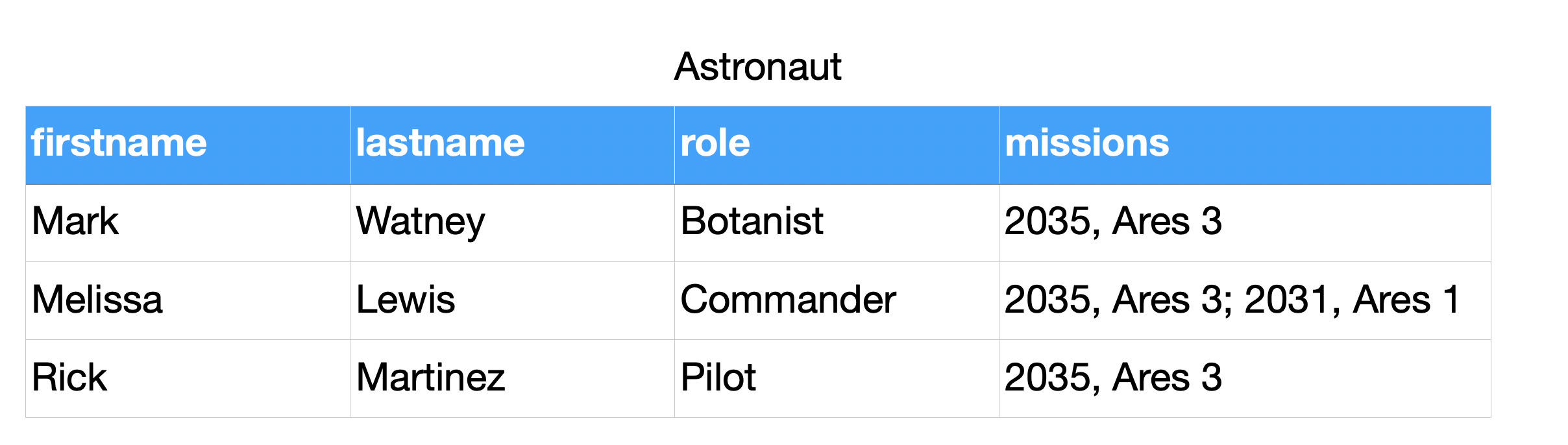

Normal forms¶
UNF: Unnormalized form
1NF: First normal form
2NF: Second normal form
3NF: Third normal form
EKNF: Elementary key normal form
BCNF: Boyce–Codd normal form
4NF: Fourth normal form
ETNF: Essential tuple normal form
5NF: Fifth normal form
DKNF: Domain-key normal form
6NF: Sixth normal form
Recap¶
DBA and Programmers use different data format than Data Scientists
Data Scientists prefer flat formats, without relations and joins
DBA and Programmers prefer relational data
For DBA and Programmers flat data formats represents data duplication
Normalization make data manipulation more consistent
Normalization uses less space and makes UPDATEs easier
Normalization causes a lot of SELECT and JOINs, which requires computation
In XXI century storage is cheap, computing power cost money
Currently SELECTs are far more common than INSERTs and UPDATEs (let say 80%-15%-5% - just a rough estimate, please don't quote this number)
Normalization does not work at large (big-data) scale
Big data requires simplified approach, and typically without any relations
Data consistency then is achieved by business logic
References¶
Assignments¶
"""
* Assignment: OOP ObjectRelations Syntax
* Complexity: easy
* Lines of code: 7 lines
* Time: 5 min
English:
1. Use Dataclass to define class `Point` with attributes:
a. `x: int` with default value `0`
b. `y: int` with default value `0`
2. Use Dataclass to define class `Path` with attributes:
a. `points: list[Point]` with default empty list
3. Run doctests - all must succeed
Polish:
1. Użyj Dataclass do zdefiniowania klasy `Point` z atrybutami:
a. `x: int` z domyślną wartością `0`
b. `y: int` z domyślną wartością `0`
2. Użyj Dataclass do zdefiniowania klasy `Path` z atrybutami:
a. `points: list[Point]` z domyślną pustą listą
3. Uruchom doctesty - wszystkie muszą się powieść
Tests:
>>> import sys; sys.tracebacklimit = 0
>>> from inspect import isclass
>>> assert isclass(Point)
>>> assert isclass(Path)
>>> assert hasattr(Point, 'x')
>>> assert hasattr(Point, 'y')
>>> Point()
Point(x=0, y=0)
>>> Point(x=0, y=0)
Point(x=0, y=0)
>>> Point(x=1, y=2)
Point(x=1, y=2)
>>> Path([Point(x=0, y=0),
... Point(x=0, y=1),
... Point(x=1, y=0)])
Path(points=[Point(x=0, y=0), Point(x=0, y=1), Point(x=1, y=0)])
"""
from dataclasses import dataclass, field
"""
* Assignment: OOP ObjectRelations HasPosition
* Complexity: easy
* Lines of code: 18 lines
* Time: 8 min
English:
1. Define class `Point`
2. Class `Point` has attributes `x: int = 0` and `y: int = 0`
3. Define class `HasPosition`
4. In `HasPosition` define method `get_position(self) -> Point`
5. In `HasPosition` define method `set_position(self, x: int, y: int) -> None`
6. In `HasPosition` define method `change_position(self, left: int = 0, right: int = 0, up: int = 0, down: int = 0) -> None`
7. Assume left-top screen corner as a initial coordinates position:
a. going right add to `x`
b. going left subtract from `x`
c. going up subtract from `y`
d. going down add to `y`
8. Run doctests - all must succeed
Polish:
1. Zdefiniuj klasę `Point`
2. Klasa `Point` ma atrybuty `x: int = 0` oraz `y: int = 0`
3. Zdefiniuj klasę `HasPosition`
4. W `HasPosition` zdefiniuj metodę `get_position(self) -> Point`
5. W `HasPosition` zdefiniuj metodę `set_position(self, x: int, y: int) -> None`
6. W `HasPosition` zdefiniuj metodę `change_position(self, left: int = 0, right: int = 0, up: int = 0, down: int = 0) -> None`
7. Przyjmij górny lewy róg ekranu za punkt początkowy:
a. idąc w prawo dodajesz `x`
b. idąc w lewo odejmujesz `x`
c. idąc w górę odejmujesz `y`
d. idąc w dół dodajesz `y`
8. Uruchom doctesty - wszystkie muszą się powieść
Tests:
>>> import sys; sys.tracebacklimit = 0
>>> from inspect import isclass, ismethod
>>> assert isclass(Point)
>>> assert isclass(HasPosition)
>>> assert hasattr(Point, 'x')
>>> assert hasattr(Point, 'y')
>>> assert hasattr(HasPosition, 'get_position')
>>> assert hasattr(HasPosition, 'set_position')
>>> assert hasattr(HasPosition, 'change_position')
>>> assert ismethod(HasPosition().get_position)
>>> assert ismethod(HasPosition().set_position)
>>> assert ismethod(HasPosition().change_position)
>>> class User(HasPosition):
... pass
>>> mark = User()
>>> mark.set_position(x=1, y=2)
>>> mark.get_position()
Point(x=1, y=2)
>>> mark.set_position(x=1, y=1)
>>> mark.change_position(right=1)
>>> mark.get_position()
Point(x=2, y=1)
>>> mark.set_position(x=1, y=1)
>>> mark.change_position(left=1)
>>> mark.get_position()
Point(x=0, y=1)
>>> mark.set_position(x=1, y=1)
>>> mark.change_position(down=1)
>>> mark.get_position()
Point(x=1, y=2)
>>> mark.set_position(x=1, y=1)
>>> mark.change_position(up=1)
>>> mark.get_position()
Point(x=1, y=0)
"""
from dataclasses import dataclass
"""
* Assignment: OOP ObjectRelations FlattenDicts
* Complexity: medium
* Lines of code: 7 lines
* Time: 13 min
English:
1. Convert `DATA` to format with one column per each attrbute for example:
a. `group1_gid`, `group2_gid`
b. `group1_name`, `group2_name`
2. Note, that enumeration starts with one
3. Collect data to `result: map`
4. Run doctests - all must succeed
Polish:
1. Przekonweruj `DATA` do formatu z jedną kolumną dla każdego atrybutu, np:
a. `group1_gid`, `group2_gid`
b. `group1_name`, `group2_name`
2. Zwróć uwagę, że enumeracja zaczyna się od jeden
3. Zbierz dane do `result: map`
4. Uruchom doctesty - wszystkie muszą się powieść
Tests:
>>> import sys; sys.tracebacklimit = 0
>>> from pprint import pprint
>>> result = list(result)
>>> assert type(result) is list
>>> assert len(result) > 0
>>> assert all(type(x) is dict for x in result)
>>> pprint(result, width=30, sort_dicts=False)
[{'firstname': 'Mark',
'lastname': 'Watney',
'group1_gid': 1,
'group1_name': 'staff'},
{'firstname': 'Melissa',
'lastname': 'Lewis',
'group1_gid': 1,
'group1_name': 'staff',
'group2_gid': 2,
'group2_name': 'admins'},
{'firstname': 'Rick',
'lastname': 'Martinez'}]
"""
DATA = [
{"firstname": "Mark", "lastname": "Watney", "groups": [
{"gid": 1, "name": "staff"}]},
{"firstname": "Melissa", "lastname": "Lewis", "groups": [
{"gid": 1, "name": "staff"},
{"gid": 2, "name": "admins"}]},
{"firstname": "Rick", "lastname": "Martinez", "groups": []},
]
# Flatten data, each mission field prefixed with mission and number
# type: list[dict]
result = ...
"""
* Assignment: OOP ObjectRelations FlattenClasses
* Complexity: medium
* Lines of code: 9 lines
* Time: 13 min
English:
1. Convert `DATA` to format with one column per each attrbute for example:
a. `group1_gid`, `group2_gid`,
b. `group1_name`, `group2_name`
2. Note, that enumeration starts with one
3. Run doctests - all must succeed
Polish:
1. Przekonweruj `DATA` do formatu z jedną kolumną dla każdego atrybutu, np:
a. `group1_gid`, `group2_gid`,
b. `group1_name`, `group2_name`
2. Zwróć uwagę, że enumeracja zaczyna się od jeden
3. Uruchom doctesty - wszystkie muszą się powieść
Hints:
* vars(obj) -> dict
Tests:
>>> import sys; sys.tracebacklimit = 0
>>> from pprint import pprint
>>> result = list(result)
>>> assert type(result) is list
>>> assert len(result) > 0
>>> assert all(type(x) is dict for x in result)
>>> pprint(result, width=30, sort_dicts=False)
[{'firstname': 'Mark',
'lastname': 'Watney',
'group1_gid': 1,
'group1_name': 'staff'},
{'firstname': 'Melissa',
'lastname': 'Lewis',
'group1_gid': 1,
'group1_name': 'staff',
'group2_gid': 2,
'group2_name': 'admins'},
{'firstname': 'Rick',
'lastname': 'Martinez'}]
"""
class User:
def __init__(self, firstname, lastname, groups=None):
self.firstname = firstname
self.lastname = lastname
self.groups = groups if groups else []
class Group:
def __init__(self, gid, name):
self.gid = gid
self.name = name
DATA = [
User('Mark', 'Watney', groups=[
Group(gid=1, name='staff')]),
User('Melissa', 'Lewis', groups=[
Group(gid=1, name='staff'),
Group(gid=2, name='admins')]),
User('Rick', 'Martinez'),
]
# Convert DATA
# type: list[dict]
result = ...
"""
* Assignment: OOP ObjectRelations Model
* Complexity: easy
* Lines of code: 16 lines
* Time: 8 min
English:
1. In `DATA` we have two classes
2. Model data using classes and relations
3. Create instances dynamically based on `DATA`
4. Run doctests - all must succeed
Polish:
1. W `DATA` mamy dwie klasy
2. Zamodeluj problem wykorzystując klasy i relacje między nimi
3. Twórz instancje dynamicznie na podstawie `DATA`
4. Uruchom doctesty - wszystkie muszą się powieść
Tests:
>>> import sys; sys.tracebacklimit = 0
>>> from pprint import pprint
>>> result = list(result)
>>> assert type(result) is list
>>> assert all(type(astro) is User for astro in result)
>>> assert all(type(addr) is Address
... for astro in result
... for addr in astro.addresses)
>>> pprint(result, sort_dicts=False)
[User(firstname='Mark',
lastname='Watney',
addresses=[Address(street='2101 E NASA Pkwy',
city='Houston',
postcode=77058,
region='Texas',
country='USA'),
Address(street='',
city='Kennedy Space Center',
postcode=32899,
region='Florida',
country='USA')]),
User(firstname='Melissa',
lastname='Lewis',
addresses=[Address(street='4800 Oak Grove Dr',
city='Pasadena',
postcode=91109,
region='California',
country='USA'),
Address(street='2825 E Ave P',
city='Palmdale',
postcode=93550,
region='California',
country='USA')]),
User(firstname='Rick', lastname='Martinez', addresses=[]),
User(firstname='Alex',
lastname='Vogel',
addresses=[Address(street='Linder Hoehe',
city='Cologne',
postcode=51147,
region='North Rhine-Westphalia',
country='Germany')])]
"""
from dataclasses import dataclass
DATA = [
{"firstname": "Mark", "lastname": "Watney", "addresses": [
{"street": "2101 E NASA Pkwy",
"city": "Houston",
"postcode": 77058,
"region": "Texas",
"country": "USA"},
{"street": "",
"city": "Kennedy Space Center",
"postcode": 32899,
"region": "Florida",
"country": "USA"}]},
{"firstname": "Melissa", "lastname": "Lewis", "addresses": [
{"street": "4800 Oak Grove Dr",
"city": "Pasadena",
"postcode": 91109,
"region": "California",
"country": "USA"},
{"street": "2825 E Ave P",
"city": "Palmdale",
"postcode": 93550,
"region": "California",
"country": "USA"}]},
{"firstname": "Rick", "lastname": "Martinez", "addresses": []},
{"firstname": "Alex", "lastname": "Vogel", "addresses": [
{"street": "Linder Hoehe",
"city": "Cologne",
"postcode": 51147,
"region": "North Rhine-Westphalia",
"country": "Germany"}]}
]
@dataclass
class Address:
...
@dataclass
class User:
...
# Iterate over `DATA` and create instances
# type: list[User]
result = ...
"""
* Assignment: OOP ObjectRelations CSV
* Complexity: medium
* Lines of code: 4 lines
* Time: 13 min
English:
1. Write data with relations to CSV format
2. Convert `DATA` to `result: list[dict[str,str]]`
3. Non-functional requirements:
a. Use `,` to separate fields
b. Use `;` to separate instances
4. Contact has zero or many addresses
5. Run doctests - all must succeed
Polish:
1. Zapisz dane relacyjne do formatu CSV
2. Przekonwertuj `DATA` do `result: list[dict[str,str]]`
3. Wymagania niefunkcjonalne:
b. Użyj `,` do oddzielenia pól
b. Użyj `;` do oddzielenia instancji
4. Kontakt ma zero lub wiele adresów
5. Uruchom doctesty - wszystkie muszą się powieść
Tests:
>>> import sys; sys.tracebacklimit = 0
>>> from pprint import pprint
>>> result = list(result)
>>> assert type(result) is list
>>> assert len(result) > 0
>>> assert all(type(x) is dict for x in result)
>>> pprint(result, width=112, sort_dicts=False) # doctest: +NORMALIZE_WHITESPACE
[{'firstname': 'Mark',
'lastname': 'Watney',
'addresses': '2101 E NASA Pkwy,Houston,77058,Texas,USA;,Kennedy Space Center,32899,Florida,USA'},
{'firstname': 'Melissa',
'lastname': 'Lewis',
'addresses': '4800 Oak Grove Dr,Pasadena,91109,California,USA;2825 E Ave P,Palmdale,93550,California,USA'},
{'firstname': 'Rick', 'lastname': 'Martinez', 'addresses': ''},
{'firstname': 'Alex',
'lastname': 'Vogel',
'addresses': 'Linder Hoehe,Cologne,51147,North Rhine-Westphalia,Germany'}]
"""
DATA = [
{"firstname": "Mark", "lastname": "Watney", "addresses": [
{"street": "2101 E NASA Pkwy",
"city": "Houston",
"postcode": 77058,
"region": "Texas",
"country": "USA"},
{"street": "",
"city": "Kennedy Space Center",
"postcode": 32899,
"region": "Florida",
"country": "USA"}]},
{"firstname": "Melissa", "lastname": "Lewis", "addresses": [
{"street": "4800 Oak Grove Dr",
"city": "Pasadena",
"postcode": 91109,
"region": "California",
"country": "USA"},
{"street": "2825 E Ave P",
"city": "Palmdale",
"postcode": 93550,
"region": "California",
"country": "USA"}]},
{"firstname": "Rick", "lastname": "Martinez", "addresses": []},
{"firstname": "Alex", "lastname": "Vogel", "addresses": [
{"street": "Linder Hoehe",
"city": "Cologne",
"postcode": 51147,
"region": "North Rhine-Westphalia",
"country": "Germany"}]}
]
# Flatten data, each address field prefixed with address and number
# type: list[dict]
result = ...